Transferring applications to a cloud offers enormous cost reductions. It also can be a trap. After placing an application on IaaS it becomes wedged into a unique software environment. For all practical purposes applications cease to be transportable from one IaaS to another IaaS. There are hundreds of cloud services that operate in this manner. IaaS is useful in offering raw computing power but it is not sufficiently flexible how it can be redeployed when conditions change.
Applications can be also placed in a Platform-as-a-Service (PaaS) cloud. All you have to do is to comply with the specific Application Interface (API) instructions and your application will run. Google, Microsoft Azure, a version of Amazon PaaS as well as other cloud services work in this way. After applications are placed in a particular cloud environment they must comply with a long list of required formats. For instance, various PaaS vendors may limit what software “frameworks” can be applied. Such “frameworks” include reusable libraries of subsystem offered by software tools such as Ruby, Java, Node.js and Grails. Some PaaS vendors may also restrict what operating systems (such as which version of Microsoft OS) can be installed. Consequently, PaaS applications will not be always transportable from one cloud vendor to another.
To support the future growth in cloud computing customers must be able to switch from one cloud vendor to another. What follows is restricted to only PaaS cases. This requires that cloud operators must offer the following features:
1. The interface between customer applications and the PaaS must be in the form of Open Source middleware, which complies with approved IEEE standards. Standard Open Source middleware will allows any application to run on any vendors’ PaaS cloud. Regardless how an application was coded it will remain transportable to any cloud, anywhere.
2. The isolation of the customer’s applications from the PaaS software and hardware will permit the retention of the customers’ intellectual property right, regardless of which cloud it may be hosted.
3. Certification by the cloud vendor to customers that that applications will remain portable regardless of configuration changes made to PaaS. This includes assurances that applications will retain the capacity for fail-over hosting by another PaaS vendor.
4. Assurance that the customers’ application code will not be altered in the PaaS cloud, regardless of the software framework used the build it.
This week, VMware introduced a new PaaS software offering called Cloud Foundry. It is available as open source software. It provides a platform for building, deploying and running cloud apps that make it possible for cloud vendors to comply with the four features listed above. Cloud Foundry is an application platform, which includes a self-service application execution engine, an automation engine for application deployment, a scriptable command line interface and development tools that ease the applications deployment processes. Cloud Foundry offers developers the tools to build out applications on public clouds, private clouds and anyplace else, whether the underlying server runs VMware or not.
Cloud Foundry is the first open PaaS that supports services to cloud firms such as Rackspace or Terremark. Cloud Foundry can be also deployed behind firewalls for enterprises can run this software as a private cloud. There is also a version of Cloud Foundry, the “Micro Cloud”, which can be installed on a personal lap top so developers can write code themselves, and then push to whichever cloud they choose. “Micro Cloud” should be therefore understood as a single developer instance of Cloud Foundry.
Cloud Foundry aims to allow developers to remove the cost and complexity of configuring infrastructure and runtime environments for applications so that they can focus on the application logic. Cloud Foundry streamlines the development, delivery and operations of modern applications, enhancing the ability of developers to deploy, run and scale applications into the cloud environment while preserving the widest choice of public and private clouds.
The objective is to get an application deployed without becoming engaged in all kinds of set-ups, such as server provisioning, specifying database parameters, inserting middleware and then testing that it’s all set up after coordinating with the data center operating personnel to accept new run-time documentation. The Cloud Foundry offers an open architecture to handle choices of developer frameworks. It accommodates choices of application infrastructure services. It enables the choosing from a variety of commercially available clouds.
Cloud Foundry overcomes limitations found in today’s PaaS solutions. Present PaaS offerings by commercial firms are held back by limited or non-standard support of development frameworks, by a lack in the variety of application services and especially in the inability to deploy applications across diverse public and private clouds.
SUMMARY
It is increasingly a prerequisite for modern software development technologies to be available as open source. DoD memorandum of October 16, 2009 offers guidance a preferred use of open source software in order to allow developers to inspect, evaluate and modify the software based on their own needs, as well as avoid the risk of lock-in. Cloud Foundry is now an open source project with a community and source code available on www.cloudfoundry.org. This provides the ultimate in extensibility and allows the community to extend and integrate Cloud Foundry with any framework, application service or infrastructure cloud. It includes a liberal licensing model encourages a broad-based community of contributors.
Cloud Foundry takes an Open Source approach to PaaS. Most of such vendor offerings restrict developer choices of frameworks, application infrastructure services and deployment clouds. The open and extensible nature of Cloud Foundry means developers will not be locked into a single framework, single set of application services or a single cloud. VMware will offer Cloud Foundry as a paid, supported product for customers as well as provide the underlying code so developers can build their own private clouds. VMware will also offer Cloud Foundry as a PaaS service in combination with a recently acquired data center in Las Vegas that presently runs data back-up services for over million customers.
Cloud Foundry allows developers to focus on applications, not machines or middleware. Traditional application deployments require developers to configure and patch systems, maintain middleware and worry about network topologies. Cloud Foundry allows you to focus on your application, not infrastructure, and deploy and scale applications in seconds. In the future interoperability of applications across several PaaS firms will matter to more and more companies especially those starting new systems. Flexibility to choose from a range of available PaaS service will become one of the factors behind the choice of trusting any one firm with the hosting and custody of its data processing.
Any DoD plans to migrate systems into a PaaS environment will henceforth have to consider whether Cloud Foundry software, or a similar offering yet to come, will be in place to assure application portability.
How to Fit DoD into the Cloud Environment?
It is now an OMB policy that DoD should start migrating into an architecture that is based on cloud-like concepts. * There are leaders who have suggested that transporting DoD applications into a Google-like environment would solve persistent problems with security, interoperability and cost.
Before anyone can subscribe to a cloud-centered solution it may be useful to examine the current state of DoD applications. What we have now is fractured and often broken, non-standard, custom-fitted and without a shared data environment.
To move thousands of such systems into a well-ordered Platform-as-a-Service or Infrastructure-as-a-Service will require enormous expenditures. It will require restructuring how systems are designed, how they can run and in what data centers they can operate.
To gain a better understanding, in a constrained budgetary environment, it may be useful to examine what are the “as-is” conditions of the existing systems before making “to-be” projections. Most importantly any plans need to be supported by funding commitments and a realistic schedule.
The OSD Deputy Chief Management Officer has defined the scope of work that needs to be done. ** It includes a list of 2,319 systems costing $23.6 billion, which represents 69% of the total DoD IT spending in FY11. *** Of the 2,319 listed systems 1,165 systems are obsolete (e.g. "legacy" or "interim"). 1,154 were labeled as systems that will survive (e.g. "core").
The following statistic shows the number of DoD business systems plotted against their respective FY11 budgets: ****
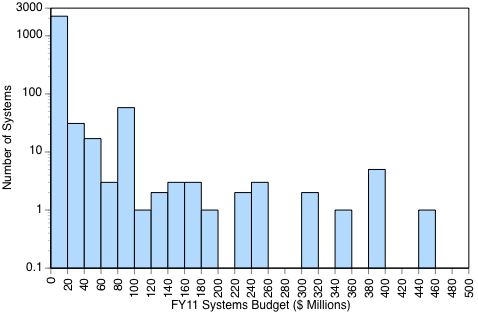
94% of the DoD 2.319 systems have budgets of less than a $20 million, with most operating with budgets of less that $1 million in FY11.
Most of these applications are categorized either as “legacy” systems to be phased out, or as “interim” systems, which have a limited life expectancy. There are 1,165 such systems, or 55% of the DoD total, which are obsolete and require ultimate replacement.
How DoD systems are distributed is illustrated in the following table. Each of these systems will contain numerous applications:

The above table shows that about half of all systems are in Financial Management and in Human Resources areas. The Business Transformation Agency, now discontinued, had spent six years attempting to unify these applications, but a large number remain in place nevertheless. Numerous independent Agencies also control 613 systems systems. Such diversification into different organizations will make any consolidations very difficult.
SUMMARY
The current proposals to ultimately merge 1,165 obsolete systems into 1,154 “core” systems may not be executable. The problem lies not with the proliferation of systems (each supporting many applications) but in the contractual arrangements for small systems, each possessing its unique infrastructure. Most of the current 2,319 systems have been built one contract at a time over a period of decades. Limitations on funding have worked out so that most of these systems ended up will unique configurations of operating systems, diverse application codes, incompatible communications and data bases that are not interoperable. With over 76% of software maintenance and upgrade in the hands of contractors incompatibilities were then a natural outcome. Meanwhile, DoD's high turnover in managerial oversight resulted in a shift of architectural control over system design to contractors.
There is no reason why the Army should not have 252 human resources systems and even more applications. There is no reason why the Navy should not have 92 financial systems with hundreds of diverse applications to manage its affairs. The issue is not the number of reporting formats - that must server diverse user needs - but the costs of funding completely separate systems to deliver such variety.
Over 60% of the current costs for Operations and Maintenance are consumed in supporting hundreds and possibly thousands of separate communications, data management and security infrastructures. Instead of such great multiplicity of infrastructures, we need only a few shared infrastructures that should be the support all of DoD's systems.
If DoD can acquire a Platform-as-a-Service or an Infrastructure-as-a-Service capability, the Army, Navy, Air Force and Agencies will be able to generate and test quickly many inexpensive (and quickly adaptable) applications to be placed on top of a few shared infrastructures. Such an arrangement would results in much cheaper applications.
DoD should not proceed with the re-writing of existing systems as has been proposed. DoD should not proceed with the consolidation of existing systems into a smaller number of surviving systems. Consolidations are slow, expensive and take a very long time,
Instead, DoD should re-direct its efforts to completely separate its infrastructure and data management from applications. The new direction should be: thousands of rapidly adaptable applications, but only a few secure cloud infrastructures for support.
* U.S. Chief Information Officer, Federal Cloud Computing Strategy, February 8, 2011
** http://dcmo.defense.gov/etp/FY2011/home.html (Master List of Systems)
*** DoD IT spending excludes the costs of the military and civilian IT workforce.
**** There are only eight projects reported with budgets greater than $500 million.
Before anyone can subscribe to a cloud-centered solution it may be useful to examine the current state of DoD applications. What we have now is fractured and often broken, non-standard, custom-fitted and without a shared data environment.
To move thousands of such systems into a well-ordered Platform-as-a-Service or Infrastructure-as-a-Service will require enormous expenditures. It will require restructuring how systems are designed, how they can run and in what data centers they can operate.
To gain a better understanding, in a constrained budgetary environment, it may be useful to examine what are the “as-is” conditions of the existing systems before making “to-be” projections. Most importantly any plans need to be supported by funding commitments and a realistic schedule.
The OSD Deputy Chief Management Officer has defined the scope of work that needs to be done. ** It includes a list of 2,319 systems costing $23.6 billion, which represents 69% of the total DoD IT spending in FY11. *** Of the 2,319 listed systems 1,165 systems are obsolete (e.g. "legacy" or "interim"). 1,154 were labeled as systems that will survive (e.g. "core").
The following statistic shows the number of DoD business systems plotted against their respective FY11 budgets: ****
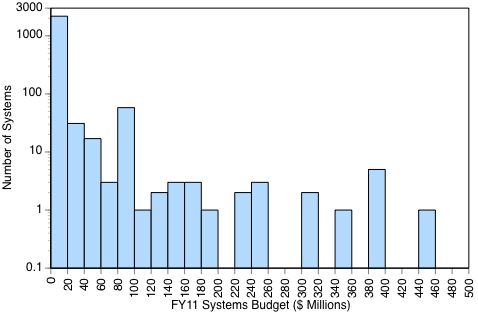
94% of the DoD 2.319 systems have budgets of less than a $20 million, with most operating with budgets of less that $1 million in FY11.
Most of these applications are categorized either as “legacy” systems to be phased out, or as “interim” systems, which have a limited life expectancy. There are 1,165 such systems, or 55% of the DoD total, which are obsolete and require ultimate replacement.
How DoD systems are distributed is illustrated in the following table. Each of these systems will contain numerous applications:
The above table shows that about half of all systems are in Financial Management and in Human Resources areas. The Business Transformation Agency, now discontinued, had spent six years attempting to unify these applications, but a large number remain in place nevertheless. Numerous independent Agencies also control 613 systems systems. Such diversification into different organizations will make any consolidations very difficult.
SUMMARY
The current proposals to ultimately merge 1,165 obsolete systems into 1,154 “core” systems may not be executable. The problem lies not with the proliferation of systems (each supporting many applications) but in the contractual arrangements for small systems, each possessing its unique infrastructure. Most of the current 2,319 systems have been built one contract at a time over a period of decades. Limitations on funding have worked out so that most of these systems ended up will unique configurations of operating systems, diverse application codes, incompatible communications and data bases that are not interoperable. With over 76% of software maintenance and upgrade in the hands of contractors incompatibilities were then a natural outcome. Meanwhile, DoD's high turnover in managerial oversight resulted in a shift of architectural control over system design to contractors.
There is no reason why the Army should not have 252 human resources systems and even more applications. There is no reason why the Navy should not have 92 financial systems with hundreds of diverse applications to manage its affairs. The issue is not the number of reporting formats - that must server diverse user needs - but the costs of funding completely separate systems to deliver such variety.
Over 60% of the current costs for Operations and Maintenance are consumed in supporting hundreds and possibly thousands of separate communications, data management and security infrastructures. Instead of such great multiplicity of infrastructures, we need only a few shared infrastructures that should be the support all of DoD's systems.
If DoD can acquire a Platform-as-a-Service or an Infrastructure-as-a-Service capability, the Army, Navy, Air Force and Agencies will be able to generate and test quickly many inexpensive (and quickly adaptable) applications to be placed on top of a few shared infrastructures. Such an arrangement would results in much cheaper applications.
DoD should not proceed with the re-writing of existing systems as has been proposed. DoD should not proceed with the consolidation of existing systems into a smaller number of surviving systems. Consolidations are slow, expensive and take a very long time,
Instead, DoD should re-direct its efforts to completely separate its infrastructure and data management from applications. The new direction should be: thousands of rapidly adaptable applications, but only a few secure cloud infrastructures for support.
* U.S. Chief Information Officer, Federal Cloud Computing Strategy, February 8, 2011
** http://dcmo.defense.gov/etp/FY2011/home.html (Master List of Systems)
*** DoD IT spending excludes the costs of the military and civilian IT workforce.
**** There are only eight projects reported with budgets greater than $500 million.
Cyber Attack on RSA
RSA (named after the inventors of public key cryptography Ron Rivest, Adi Shamir and Leonard Adleman) is one of the foremost providers of security, risk and compliance solutions. When RSA SecureID token was recently attacked and compromised, this raised the question of how good are the safeguards of the keepers of everybody’s security safeguards. *
The RSA attack was waged in the form of an Advanced Persistent Threat (APT). Information was getting extracted from RSA's protectors of the RSA’s SecurID two-factor authentication products.
“The attacker in this case sent two different phishing emails over a two-day period. The two emails were sent to two small groups of employees who were not high profile or high value targets. The email subject line read '2011 Recruitment Plan. The email was crafted well enough to trick one of the employees to retrieve it from their Junk mail folder, and open the attached excel file. It was a spreadsheet titled '2011 Recruitment plan.xls. The spreadsheet contained a zero-day exploit that installs a backdoor through Adobe Flash vulnerability (CVE-2011-0609).” **
The attack on RSA can be considered to be a textbook example of a targeted phishing attack, or a “spear fishing attack”. What the attacker goes after and obtains once inside the compromised network largely depends on which user he was able to fool and what were the victim's access rights and position in the organization.
The malware that the attacker installed was a variant of the well-known Poison Ivy remote administration tool, which then connected to a remote machine. The emails were circulated to a small group of RSA employees. At least one must have pulled the message out of a spam folder, opened it and then opened the malicious attachment.
In studying the attack form RSA concluded that the attacker first harvested access credentials from the compromised users (user, domain admin, and service accounts). Then proceeded with an escalation on non-administrative users that had access to servers that contained the critically protected “seed” number that is used to generate SecureID numbers ever 60 seconds.
The process used by the attacker was not only sophisticated but also complex, involving several methods: "The attacker in the RSA case established access to staging servers at key aggregation points; this was done to get ready for extraction. Then they went into the servers of interest, removed data and moved it to internal staging servers where the data was aggregated, compressed and encrypted for extraction. The attacker then used FTP to transfer many passwords protected by the RSA file server to an outside staging server at an external, compromised machine at a hosting provider. The files were subsequently pulled by the attacker and removed from the external compromised host to remove any traces of the attack.” *** It can be assumed that the attacker must have had inside information how the RSA methods could be exploited.
SUMMARY
The successful penetration of a highly guarded and well protected source of an RSA security offering should be seen as a warning that a persistent and highly skilled attacker can break down even the strongest defenses.
In this case we have a “spear fishing” exploit, which shows that the attacker must have possessed a great deal of inside information in order to direct the placement of the Poison Ivy tools. Using a known vulnerability (in Adobe Flash) as a vehicle only shows that multiple exploit vehicles can be exploited simultaneously to achieve the desired results.
As is almost always the case, it was a human lapse that allowed the attack on RSA to proceed. Opening a plausibly labeled attachment to e-mail is something that can happen easily, even by people who have special security training.
The only known remedy in a situation like the RSA attack, assuming that somebody, somewhere would be easily fooled to open an attachment, is to enforce the discipline of permitting the opening of e-mails only from persons whose identify is independently certified. Even then there is always a possibility that an invalid certification of identity may somehow creep into DoD. Consequently, a high priority must be placed on instant revocation of any PKI certification of identity.
*http://www.rsa.com/node.aspx?id=3872
** https://threatpost.com/en_us/blogs/rsa-securid-attack-was-phishing-excel-spreadsheet-040111
*** Adobe Flash vulnerability (CVE-2011-0609)
The RSA attack was waged in the form of an Advanced Persistent Threat (APT). Information was getting extracted from RSA's protectors of the RSA’s SecurID two-factor authentication products.
“The attacker in this case sent two different phishing emails over a two-day period. The two emails were sent to two small groups of employees who were not high profile or high value targets. The email subject line read '2011 Recruitment Plan. The email was crafted well enough to trick one of the employees to retrieve it from their Junk mail folder, and open the attached excel file. It was a spreadsheet titled '2011 Recruitment plan.xls. The spreadsheet contained a zero-day exploit that installs a backdoor through Adobe Flash vulnerability (CVE-2011-0609).” **
The attack on RSA can be considered to be a textbook example of a targeted phishing attack, or a “spear fishing attack”. What the attacker goes after and obtains once inside the compromised network largely depends on which user he was able to fool and what were the victim's access rights and position in the organization.
The malware that the attacker installed was a variant of the well-known Poison Ivy remote administration tool, which then connected to a remote machine. The emails were circulated to a small group of RSA employees. At least one must have pulled the message out of a spam folder, opened it and then opened the malicious attachment.
In studying the attack form RSA concluded that the attacker first harvested access credentials from the compromised users (user, domain admin, and service accounts). Then proceeded with an escalation on non-administrative users that had access to servers that contained the critically protected “seed” number that is used to generate SecureID numbers ever 60 seconds.
The process used by the attacker was not only sophisticated but also complex, involving several methods: "The attacker in the RSA case established access to staging servers at key aggregation points; this was done to get ready for extraction. Then they went into the servers of interest, removed data and moved it to internal staging servers where the data was aggregated, compressed and encrypted for extraction. The attacker then used FTP to transfer many passwords protected by the RSA file server to an outside staging server at an external, compromised machine at a hosting provider. The files were subsequently pulled by the attacker and removed from the external compromised host to remove any traces of the attack.” *** It can be assumed that the attacker must have had inside information how the RSA methods could be exploited.
SUMMARY
The successful penetration of a highly guarded and well protected source of an RSA security offering should be seen as a warning that a persistent and highly skilled attacker can break down even the strongest defenses.
In this case we have a “spear fishing” exploit, which shows that the attacker must have possessed a great deal of inside information in order to direct the placement of the Poison Ivy tools. Using a known vulnerability (in Adobe Flash) as a vehicle only shows that multiple exploit vehicles can be exploited simultaneously to achieve the desired results.
As is almost always the case, it was a human lapse that allowed the attack on RSA to proceed. Opening a plausibly labeled attachment to e-mail is something that can happen easily, even by people who have special security training.
The only known remedy in a situation like the RSA attack, assuming that somebody, somewhere would be easily fooled to open an attachment, is to enforce the discipline of permitting the opening of e-mails only from persons whose identify is independently certified. Even then there is always a possibility that an invalid certification of identity may somehow creep into DoD. Consequently, a high priority must be placed on instant revocation of any PKI certification of identity.
*http://www.rsa.com/node.aspx?id=3872
** https://threatpost.com/en_us/blogs/rsa-securid-attack-was-phishing-excel-spreadsheet-040111
*** Adobe Flash vulnerability (CVE-2011-0609)
Continuity of Operations in the Cloud
One of the primary benefits from cloud data operations is the capacity to perform complete backups and to support Continuity of Operations Plans (COOP). COOP recovers operations whenever there is a failure.
In the past data centers were small. Files that needed backup were relatively small, hardly ever exceeding a terabyte. Real-time transactions were rare. High priority processing could be handled by acquiring redundant computing assets that matched the unique configurations of each data center. COOP was managed as a bilateral arrangement. Since hardware and software interoperability across data centers was rare, to restart processing at another side was time consuming. Luckily, data centers were operating at a low level of capacity utilization, which made the insertion of unexpected workloads manageable.
The current DoD environment for COOP cannot use the plans that have been set in place during an era when batch processing was the dominant data center workload. Files are now getting consolidated into cross-functional repositories, often approaching petabytes of data. The urgency of restoring operations is much greater as the processing of information supports a workflow that combines diverse activities.
Desktops and laptops, that used to be self-sustaining, are now completely dependent on the restoration of their screens with sub-second response time. There has been a rapid growth in the number of real-time applications that cannot tolerate delays. What used to be bilateral COOP arrangement is not acceptable any more as DoD is pursuing data server consolidations. The merger of data is based on virtualization of all assets that eliminates much of the spare computer processing capacity.
The current conditions dictate that for rapid fail-over backup data centers must be interoperable. Hardware and software configurations must be able to handle interchangeable files and programs. A failure at any one location must allow for the processing the workloads without interruption at another site. To achieve an assured failover the original and the backup sites must be geographically separate to minimize the effects of natural disasters or of man-caused disruptions. What used to be the favorite COOP plan of loading a station wagon and driving relatively short distances with removable disk packs is not feasible any more. Petabyte data files cannot be moved because they do not exist in isolation. Data center operations are tightly wrapped into a complex of hypervisors, security appliances, emulators, translators and communications devices.
Under fail-over conditions the transfers of data between data centers must be manageable. The affected data centers must be able to exchange large amounts of data over high capacity circuits. Is it possible to start thinking about a COOP arrangement that will operate with fail-overs that are executed instantly over high capacity circuits? How much circuit capacity is required for claiming that two (or more) data centers could be interchangeable?
The following table shows the capacities of different circuits as well as the size of the files that would be have to be transferred for a workable COOP plan:

Transfers of files between small data centers (each with 10 Terabytes of files) would take up to 28 hours using an extremely high capacity circuit (100 MB/Sec). That is not viable.
DoD transaction processing, including sensor data, involves processing of at least one petabyte per date at present, and probably much more in the future. It would take 17 weeks to back up a single petabyte of data from one data center to another even if the highest available circuit capacity of 100 MB/sec is used. That is clearly not viable.
We must therefore conclude that the idea of achieving fail-over backup capabilities by electronic means cannot be included in any COOP plans.
SUMMARY
COOP for the cloud environment must be based on multiple data centers that operate in synchronization with identical software, with matching technologies of computing assets and with comparable data center management practices. This does not call for a strict comparability of every application. What matters will be an identity of the DoD private cloud to act as a Platform-as-a-Service utility, with standard Application Processing Interfaces (APIs).
OMB has mandated that for FY12 all new DoD applications will have to cloud implementation options. Rethinking how to organize the DoD cloud environment for COOP will dictate how that can be accomplished.
In the past data centers were small. Files that needed backup were relatively small, hardly ever exceeding a terabyte. Real-time transactions were rare. High priority processing could be handled by acquiring redundant computing assets that matched the unique configurations of each data center. COOP was managed as a bilateral arrangement. Since hardware and software interoperability across data centers was rare, to restart processing at another side was time consuming. Luckily, data centers were operating at a low level of capacity utilization, which made the insertion of unexpected workloads manageable.
The current DoD environment for COOP cannot use the plans that have been set in place during an era when batch processing was the dominant data center workload. Files are now getting consolidated into cross-functional repositories, often approaching petabytes of data. The urgency of restoring operations is much greater as the processing of information supports a workflow that combines diverse activities.
Desktops and laptops, that used to be self-sustaining, are now completely dependent on the restoration of their screens with sub-second response time. There has been a rapid growth in the number of real-time applications that cannot tolerate delays. What used to be bilateral COOP arrangement is not acceptable any more as DoD is pursuing data server consolidations. The merger of data is based on virtualization of all assets that eliminates much of the spare computer processing capacity.
The current conditions dictate that for rapid fail-over backup data centers must be interoperable. Hardware and software configurations must be able to handle interchangeable files and programs. A failure at any one location must allow for the processing the workloads without interruption at another site. To achieve an assured failover the original and the backup sites must be geographically separate to minimize the effects of natural disasters or of man-caused disruptions. What used to be the favorite COOP plan of loading a station wagon and driving relatively short distances with removable disk packs is not feasible any more. Petabyte data files cannot be moved because they do not exist in isolation. Data center operations are tightly wrapped into a complex of hypervisors, security appliances, emulators, translators and communications devices.
Under fail-over conditions the transfers of data between data centers must be manageable. The affected data centers must be able to exchange large amounts of data over high capacity circuits. Is it possible to start thinking about a COOP arrangement that will operate with fail-overs that are executed instantly over high capacity circuits? How much circuit capacity is required for claiming that two (or more) data centers could be interchangeable?
The following table shows the capacities of different circuits as well as the size of the files that would be have to be transferred for a workable COOP plan:
Transfers of files between small data centers (each with 10 Terabytes of files) would take up to 28 hours using an extremely high capacity circuit (100 MB/Sec). That is not viable.
DoD transaction processing, including sensor data, involves processing of at least one petabyte per date at present, and probably much more in the future. It would take 17 weeks to back up a single petabyte of data from one data center to another even if the highest available circuit capacity of 100 MB/sec is used. That is clearly not viable.
We must therefore conclude that the idea of achieving fail-over backup capabilities by electronic means cannot be included in any COOP plans.
SUMMARY
COOP for the cloud environment must be based on multiple data centers that operate in synchronization with identical software, with matching technologies of computing assets and with comparable data center management practices. This does not call for a strict comparability of every application. What matters will be an identity of the DoD private cloud to act as a Platform-as-a-Service utility, with standard Application Processing Interfaces (APIs).
OMB has mandated that for FY12 all new DoD applications will have to cloud implementation options. Rethinking how to organize the DoD cloud environment for COOP will dictate how that can be accomplished.
Subscribe to:
Comments (Atom)