The most recent three-day failure of the Amazon cloud to deliver customer services highlights the importance of understanding what is the meaning of promised levels of service.
The Amazon EC2 SLA guarantees 99.95% availability of services within a Region over a trailing 365-day period. A customer then qualifies for SLA Service Credits for the fees and charges a customer would incur otherwise.
When signing a Service Level Agreement the following needs attention:
1. A 99.95% availability over a 365-day period means that Amazon will deliver contracted for services except for 2,628 minutes per year (or 43.8 hours).
2. Failure rates are not uniformly distributed. Data center downtime statistics shows a steep declining exponential curve. There are few large failures and many small failures. Therefore the chances of a 263 minutes failure is at least 37 times greater than the calculated average outage.
3. The Amazon SLA hedged its promise by offering availability “within a computing Region”, which was defined as a physically distinct, independent infrastructure backing up within the region. Contractually Amazon did not have a failure because more than one processing region was involved.
4. The amount of liability for damages that Amazon incurred was not specified. The Amazon SLAs compensate only for unbilled fees. The damage for loss in revenue will always exceed the costs for transaction processing. Inclusion of liability insurance must be included in the costs for delivering cloud services.
SUMMARY
SLAs should be defined by means of uptime statistics. The uptime should be stated in days and not as an annual interval. The customer is buying online support for web-based applications. Availability in support of web services is critical. What is missing in the Amazon SLAs is a contractual statement as to the time it will take to completely reconstitute operations in minutes, not days, if critical business operations are involved.
Missing from the SLAs is the all-important issue of a guarantee of the latency the cloud service will be providing. The standard here is Google, with average response to searches in 30 milliseconds and rarely peaking over 80 milliseconds. Cloud vendor suppliers should not be allowed to trade off uptime vs. latency.
Uptime (with defined geographic limits), time to recover (hours), time to reconstitute to full operations (minutes) and min-max latency (milliseconds) are the metrics for cloud operations, whether public or private. A clear definition of measurements accompanied with rigorous definitions of SLA terms is a necessity.
Performance of computing services used to be evaluated by polling of customer opinions. Such an approach, similar to beauty contests, cannot be applied any more. Cloud services are the engines of the global trade, processing trillions of dollars or transactions every day. Performance metrics and a liability for losses must be included in SLA negotiations.
Amazon Cloud Computing Failure
Yesterday Amazon Web Services (AWS) reported an outage of its processing services in the Northern Virginia data centers. Multiple web sites were out of service. This attracted widespread attention from evening TV news reports and from major daily newspapers. The word is out that cloud computing could be unreliable.
A review of uptime performance of AWS showed that all cloud services performed well at all times with the exception Only EC2, RDS and Beanstalk in Virginia for a part of one day. AWS in Europe and Asia Pacific continued to run perfectly.

The reported outage calls the Amazon back-up arrangements into question. Did Amazon provide for sufficient redundancy? Was there sufficient back ups available for the failed applications available at other sites?
In retrospect the affected customers, who included only a limited set of customers, such as Foursquare, Reddit, Quora and Hootsuite web sites, could have bought insurance against failure. They could have signed Service Level Agreements (SLA) for a remote site fail-over.
Such arrangement can be expensive, depending on the back-up options chosen. However, computers do fail.
Amazon's service-level commitment provides 99.95% availability. This is insufficient because this allows for average annual downtime of 263 minutes. If you apply the exponential distribution of the probability of failure, the chance of computer downtime is even greater than indicated by the average.
If customers run major businesses on top of Amazon, and suffer large dollar amounts of dollars in lost revenue, why not pay for fail-over at another site? Was there money saved by not providing redundancy worthy of the risk? *
Amazon is liable to compensate only for the loss of the customer’s cloud costs. They are not responsible for the customer’s losses. Calculating the worth of fail-over insurance should be a simple matter at the time when the SLAs are negotiated.
Indeed, Amazon backed up the workloads, but only within the processing zones that were located at US-EAST-1. Though data was replicated, the failure remained local. Why did not Amazon (or the customer) provide for a California backup? Why was the East Coast application not replicated to run simultaneously across multiple cloud platforms from different vendors?
For 100% uptime it is necessary to run across multiple zones not only from the same vendor who is likely to have identical bugs. Different locations from the identical cloud provider will never be totally sufficient. Even Google, with 27 data centers has problems in running Gmail. The simpler idea of sticking just with Amazon and balancing applications across multiple regions may be insufficient for critical applications.
SUMMARY
Customers should contract with multiple providers, at multiple locations, for survival of applications that warrants 100.00% uptime. Cloud computing, and particularly the Platform-as-a-Service (PaaS) offer much simpler deployment and management of applications. These are independent of the underlying proprietary infrastructures, which should make the selection of multiple vendors feasible. However, building an application to work across multiple vendors requires strict conformance to standards and a disciplined commitment to interoperability across multiple clouds. As yet, DoD has to demonstrate that it has IT executives who can steer the developers into such directions.
Anytime there is a cloud outage, some will call into question all cloud computing. That is not a valid argument. Every computer has downtime. The difference with cloud computing is how we manage to pay for risk. The Amazon cloud failure yesterday offers a very useful lesson how to start getting ready for the assured continuity of cyber operations, which make error free uptime a requirement.
* http://pstrassmann.blogspot.com/2011/04/continuity-of-operations-in-cloud.html
A review of uptime performance of AWS showed that all cloud services performed well at all times with the exception Only EC2, RDS and Beanstalk in Virginia for a part of one day. AWS in Europe and Asia Pacific continued to run perfectly.

The reported outage calls the Amazon back-up arrangements into question. Did Amazon provide for sufficient redundancy? Was there sufficient back ups available for the failed applications available at other sites?
In retrospect the affected customers, who included only a limited set of customers, such as Foursquare, Reddit, Quora and Hootsuite web sites, could have bought insurance against failure. They could have signed Service Level Agreements (SLA) for a remote site fail-over.
Such arrangement can be expensive, depending on the back-up options chosen. However, computers do fail.
Amazon's service-level commitment provides 99.95% availability. This is insufficient because this allows for average annual downtime of 263 minutes. If you apply the exponential distribution of the probability of failure, the chance of computer downtime is even greater than indicated by the average.
If customers run major businesses on top of Amazon, and suffer large dollar amounts of dollars in lost revenue, why not pay for fail-over at another site? Was there money saved by not providing redundancy worthy of the risk? *
Amazon is liable to compensate only for the loss of the customer’s cloud costs. They are not responsible for the customer’s losses. Calculating the worth of fail-over insurance should be a simple matter at the time when the SLAs are negotiated.
Indeed, Amazon backed up the workloads, but only within the processing zones that were located at US-EAST-1. Though data was replicated, the failure remained local. Why did not Amazon (or the customer) provide for a California backup? Why was the East Coast application not replicated to run simultaneously across multiple cloud platforms from different vendors?
For 100% uptime it is necessary to run across multiple zones not only from the same vendor who is likely to have identical bugs. Different locations from the identical cloud provider will never be totally sufficient. Even Google, with 27 data centers has problems in running Gmail. The simpler idea of sticking just with Amazon and balancing applications across multiple regions may be insufficient for critical applications.
SUMMARY
Customers should contract with multiple providers, at multiple locations, for survival of applications that warrants 100.00% uptime. Cloud computing, and particularly the Platform-as-a-Service (PaaS) offer much simpler deployment and management of applications. These are independent of the underlying proprietary infrastructures, which should make the selection of multiple vendors feasible. However, building an application to work across multiple vendors requires strict conformance to standards and a disciplined commitment to interoperability across multiple clouds. As yet, DoD has to demonstrate that it has IT executives who can steer the developers into such directions.
Anytime there is a cloud outage, some will call into question all cloud computing. That is not a valid argument. Every computer has downtime. The difference with cloud computing is how we manage to pay for risk. The Amazon cloud failure yesterday offers a very useful lesson how to start getting ready for the assured continuity of cyber operations, which make error free uptime a requirement.
* http://pstrassmann.blogspot.com/2011/04/continuity-of-operations-in-cloud.html
Will Standards Define the Cloud Environment?
For further progress of the development of cloud operations it will be necessary to establish standard that will assure that the cloud environment is interoperable. It is the sense of this blog to describe the formats that will assure a customer that any application, once placed in the cloud environment, will be transportable to any other cloud.
Standards are critical with increasing pressure to ensure that cloud technology investments remain viable for years to come. Standards allow CIOs to select products that best suit their needs today–regardless of vendor–while helping to ensure that no proprietary constraints arise when new systems are put in place in the future.
The goal of any Open Cloud Standards is to enable portability and interoperability between private clouds within enterprises, hosted private clouds or public cloud services.

The prime mover of cloud standards is the Cloud Security Alliance (CSA), which includes CSA Security Guidance for Cloud Computing, CSA Cloud Controls and CSA Top Threats * There is also a CloudAudit Group associated with CSA. It is a volunteer cross-industry effort on cloud, networking, security, audit, assurance and architecture backgrounds.
The Distributed Management Task Force (DMTF) has published the Open Virtualization Format (OVF), which is a defined standard for the portability and deployment of virtual appliances. OVF enables simplified deployment of virtual appliances across multiple virtualization platforms. A virtual appliance is a virtual machine image designed to run on any virtualization platform. Virtual appliances are a subset of the broader class of software appliances, which eliminate the installation, configuration and maintenance costs associated with running complex software.
OVF is a common packaging format for independent software vendors (ISVs) to package and securely distribute virtual appliances, enabling cross-platform portability. By packaging virtual appliances in OVF, ISVs can create a single, pre-packaged appliance that can run on customers’ virtualization platforms of choice.
The International Organization for Standardization (ISO) manages the Study Group on Cloud Computing (SGCC), which provide a taxonomy and terminology Cloud Computing and assesses the current state of standardization in Cloud Computing.
The European Telecommunications Standards Institute (ETSI) has formed a TC Cloud Interest Group to help with the formulation of standards for cloud computing. So far its work is based entirely on US standards bodies.
The National Institute of Standards and Technology (NIST) role in cloud computing is to promote the effective and secure use of the technology within government and industry by providing technical guidance and promoting standards. NIST’s work to date has focused on the definition and taxonomy of cloud computing. Such definitions serve as a foundation for our upcoming publications on cloud models, architectures, and deployment strategies. So far no formal software protocols have been issued.
The Open Grid Forum (OGF) has organized the Open Cloud Computing Interface Group (OCCI) defines general-purpose specifications for cloud-based interactions. The current OCCI specifications consist of three procedural documents.
The Object Management Group (OMG) has formed the Open Cloud Consortium (OCC) which has generated set of scripts which generate large, distributed data sets suitable for testing and benchmarking software designed to perform parallel processing on large data sets.
The Organization for the Advancement of Structure Information Standards (OASIS) has formed the OASIS Cloud-Specific Technical Committees, which address the security issues posed by identity management in cloud computing.
The Storage Networking Industry Associations (SNIA) has created the Cloud Storage Technical Work Group for the purpose of developing SNIA Architecture related to system implementations of Cloud Storage technology.
The Open Group has formed the Cloud Work Group to create a common understanding among buyers and suppliers of how enterprises of all sizes and scales of operation can include Cloud Computing technology in their architectures to realize its benefits.
The TM Forum is an industry association focused on enabling IT services for operators in the communications, media and cloud service markets. It operates the TM Forum's Cloud Services Initiative to promote the use of cloud standards.
The Institute of Electrical and Electronics Engineers (IEEE) is in the process of organizing the IEEE P2301 group that will produce a guide for cloud portability and interoperability profiles.
SUMMARY
I have counted over twenty organizations involved with the standardization of how to manage cloud computing. So far, only one formal standard that addressed virtualization has been published, though not widely adopted as yet.
It is clear that the various standards organizations are lagging far behind the actual work done by cloud vendors who are working hard to buttress their competitive positions as proprietary (or hard to dislodge) suppliers. From the standpoint of enabling portability of applications across various cloud service offerings we do not find any evidence that vendors would be relying on standards bodies to make customers interoperable.
As was the case with Microsoft thirty years ago, interoperability of the cloud environment will not be achieved by means of public standards. It will be delivered by means of adoptions that will be implemented by a few of the strongest software vendors.
* https://cloudsecurityalliance.org/
Standards are critical with increasing pressure to ensure that cloud technology investments remain viable for years to come. Standards allow CIOs to select products that best suit their needs today–regardless of vendor–while helping to ensure that no proprietary constraints arise when new systems are put in place in the future.
The goal of any Open Cloud Standards is to enable portability and interoperability between private clouds within enterprises, hosted private clouds or public cloud services.

The prime mover of cloud standards is the Cloud Security Alliance (CSA), which includes CSA Security Guidance for Cloud Computing, CSA Cloud Controls and CSA Top Threats * There is also a CloudAudit Group associated with CSA. It is a volunteer cross-industry effort on cloud, networking, security, audit, assurance and architecture backgrounds.
The Distributed Management Task Force (DMTF) has published the Open Virtualization Format (OVF), which is a defined standard for the portability and deployment of virtual appliances. OVF enables simplified deployment of virtual appliances across multiple virtualization platforms. A virtual appliance is a virtual machine image designed to run on any virtualization platform. Virtual appliances are a subset of the broader class of software appliances, which eliminate the installation, configuration and maintenance costs associated with running complex software.
OVF is a common packaging format for independent software vendors (ISVs) to package and securely distribute virtual appliances, enabling cross-platform portability. By packaging virtual appliances in OVF, ISVs can create a single, pre-packaged appliance that can run on customers’ virtualization platforms of choice.
The International Organization for Standardization (ISO) manages the Study Group on Cloud Computing (SGCC), which provide a taxonomy and terminology Cloud Computing and assesses the current state of standardization in Cloud Computing.
The European Telecommunications Standards Institute (ETSI) has formed a TC Cloud Interest Group to help with the formulation of standards for cloud computing. So far its work is based entirely on US standards bodies.
The National Institute of Standards and Technology (NIST) role in cloud computing is to promote the effective and secure use of the technology within government and industry by providing technical guidance and promoting standards. NIST’s work to date has focused on the definition and taxonomy of cloud computing. Such definitions serve as a foundation for our upcoming publications on cloud models, architectures, and deployment strategies. So far no formal software protocols have been issued.
The Open Grid Forum (OGF) has organized the Open Cloud Computing Interface Group (OCCI) defines general-purpose specifications for cloud-based interactions. The current OCCI specifications consist of three procedural documents.
The Object Management Group (OMG) has formed the Open Cloud Consortium (OCC) which has generated set of scripts which generate large, distributed data sets suitable for testing and benchmarking software designed to perform parallel processing on large data sets.
The Organization for the Advancement of Structure Information Standards (OASIS) has formed the OASIS Cloud-Specific Technical Committees, which address the security issues posed by identity management in cloud computing.
The Storage Networking Industry Associations (SNIA) has created the Cloud Storage Technical Work Group for the purpose of developing SNIA Architecture related to system implementations of Cloud Storage technology.
The Open Group has formed the Cloud Work Group to create a common understanding among buyers and suppliers of how enterprises of all sizes and scales of operation can include Cloud Computing technology in their architectures to realize its benefits.
The TM Forum is an industry association focused on enabling IT services for operators in the communications, media and cloud service markets. It operates the TM Forum's Cloud Services Initiative to promote the use of cloud standards.
The Institute of Electrical and Electronics Engineers (IEEE) is in the process of organizing the IEEE P2301 group that will produce a guide for cloud portability and interoperability profiles.
SUMMARY
I have counted over twenty organizations involved with the standardization of how to manage cloud computing. So far, only one formal standard that addressed virtualization has been published, though not widely adopted as yet.
It is clear that the various standards organizations are lagging far behind the actual work done by cloud vendors who are working hard to buttress their competitive positions as proprietary (or hard to dislodge) suppliers. From the standpoint of enabling portability of applications across various cloud service offerings we do not find any evidence that vendors would be relying on standards bodies to make customers interoperable.
As was the case with Microsoft thirty years ago, interoperability of the cloud environment will not be achieved by means of public standards. It will be delivered by means of adoptions that will be implemented by a few of the strongest software vendors.
* https://cloudsecurityalliance.org/
Status Report on IPv6
In the February 2, 2011 blog about IPv6 I concluded that: “ … Despite high-level policy mandates promulgated in 2003 and in 2010 the IPv4 to IPv6 conversions will not happen very soon.” *
Various reports agreed that the scarcity of IP addresses was a geographic occurrence. This was caused by insufficient initial allocation of addresses to the Pacific region. There was also a widespread understanding that there was no shortage of IP addresses when examined from a global point of view.
For the first time we have now a credible report about the current levels of IPv6 usage, as a percentage of all Internet traffic. This was collected from six major telecomm carriers. ** The findings are surprising:

The IPv6 traffic in the last three months averaged less than 0.20% of total traffic. That can be considered to be a negligible amount.
SUMMARY
The traffic statistics sample shows that the highly promoted urgency to migrate into IPv6 has no merit. In the foreseeable future, the solution to the local scarcity of IP addresses can be found through a reallocation of IP surplus rather then engaging in a costly campaign to bring about the restructuring of systems.
Meanwhile an active market has been created for the more scarce IPv4 addresses. As a part of the bankruptcy settlement Microsoft has offered to buy Nortel’s 666,624 IPv4 addresses for $7.5 million.
That is $11.25 per address. Since IPv4 addresses are “virtual property” they can be sold nevertheless.
The IPv4 protocol has 4.3 billion addresses. As of the end of 2010 only 533 million of these numbers has been assigned. * This leaves 3.8 billion addresses potentially available for deployment. If Microsoft pegged the worth of an IPv4 address at $11.25 then there is a potential of $40 billion dollars worth of virtual numbers available somewhere for re-allocation.
* http://pstrassmann.blogspot.com/2011/02/are-ipv4-addresses-exhausted.html
** http://asert.arbornetworks.com/2011/04/six-months-six-providers-and-ipv6/
Various reports agreed that the scarcity of IP addresses was a geographic occurrence. This was caused by insufficient initial allocation of addresses to the Pacific region. There was also a widespread understanding that there was no shortage of IP addresses when examined from a global point of view.
For the first time we have now a credible report about the current levels of IPv6 usage, as a percentage of all Internet traffic. This was collected from six major telecomm carriers. ** The findings are surprising:

The IPv6 traffic in the last three months averaged less than 0.20% of total traffic. That can be considered to be a negligible amount.
SUMMARY
The traffic statistics sample shows that the highly promoted urgency to migrate into IPv6 has no merit. In the foreseeable future, the solution to the local scarcity of IP addresses can be found through a reallocation of IP surplus rather then engaging in a costly campaign to bring about the restructuring of systems.
Meanwhile an active market has been created for the more scarce IPv4 addresses. As a part of the bankruptcy settlement Microsoft has offered to buy Nortel’s 666,624 IPv4 addresses for $7.5 million.
That is $11.25 per address. Since IPv4 addresses are “virtual property” they can be sold nevertheless.
The IPv4 protocol has 4.3 billion addresses. As of the end of 2010 only 533 million of these numbers has been assigned. * This leaves 3.8 billion addresses potentially available for deployment. If Microsoft pegged the worth of an IPv4 address at $11.25 then there is a potential of $40 billion dollars worth of virtual numbers available somewhere for re-allocation.
* http://pstrassmann.blogspot.com/2011/02/are-ipv4-addresses-exhausted.html
** http://asert.arbornetworks.com/2011/04/six-months-six-providers-and-ipv6/
Shifting to Infrastructure-as-a-Service?
Infrastructure-as-a-Service (IaaS) is the DoD’s first implementation of cloud computing. DISA has set up the Rapid Access Computing Environment (RACE) program as offering IaaS solutions. IaaS is based on self-service provisioning where DISA acts as a broker that arranges access to cloud operators such as Amazon, Google, Rackspace, Terremark and others. *
Whether DoD customers must access IaaS services only through DISA, acting as an intermediary, is not clear. Anyone can gain access to IaaS with only a credit card. When contractors work on an Army system, whether they use in-house servers or much cheaper cloud company servers will not be readily apparent.
So far RACE has been used for development and testing, which is performed by DoD contractors. Many military applications have been already developed and tested using cloud-provided processing capacity.
DISA wants now to progress further to see if DoD can start using RACE for the execution the entire applications life cycle process, including production.
Accessing IaaS services is not a simple matter. An application must be placed on top of a proprietary middleware packages. These packages are needed so that an application can function within the vendor specific environment. In effect, such a middleware represents a potential lock-in for a customer seeking an IaaS place for an application to run on.
Here is an example of the middleware options – many are mandatory – that must be deployed before an application can be tested and run on Amazon Web Services (AWS), one of the most popular IaaS services:

Depending on the purpose for using IaaS, a customer will have to define the settings for each of the middleware options. This may differ for different situations and can create - de facto - a condition where moving an application to a different IaaS vendor would be laborious.
When it comes to running applications in a production environment, IaaS may not offer an advantage from a cost standpoint. Hosting an application database on the Amazon proprietary offering, such as the Amazon RDS, could ruin the interoperability with related of IaaS databases that are run by other IaaS vendors. This would be so particularly in the case of real-time operations.
SUMMARY
Before DoD proceeds with the placement of its run-time operations with diverse IaaS vendors, DISA must see to it that standards are in place that will assure interoperability and compatibility across proprietary solutions offered by competing IaaS vendors such as Oracle, which supports only Oracle specific IaaS.
Verification of interoperability will have to take place whenever there is an exodus to IaaS providers from the Army, Navy and Air Force instead of consolidating data centers into the Defense Enterprise Computing Centers (DECCs).
Current targets to eliminate most of DoD’s 772 data centers could be potentially met by shifting the computer processing workload to IaaS firms. Contractor headcount will be reduced and computer assets will be removed form DoD books. This will look good because it would deliver reductions that meet OMB numerical targets. However, if such moves are not tightly managed by means of standards, DoD may end up with an even more fractured operating environment than is currently that case.
*http://defensesystems.com/Articles/2011/03/29/Cover-Story-DISA-charts-cloud-strategy.aspx?Page=2
Whether DoD customers must access IaaS services only through DISA, acting as an intermediary, is not clear. Anyone can gain access to IaaS with only a credit card. When contractors work on an Army system, whether they use in-house servers or much cheaper cloud company servers will not be readily apparent.
So far RACE has been used for development and testing, which is performed by DoD contractors. Many military applications have been already developed and tested using cloud-provided processing capacity.
DISA wants now to progress further to see if DoD can start using RACE for the execution the entire applications life cycle process, including production.
Accessing IaaS services is not a simple matter. An application must be placed on top of a proprietary middleware packages. These packages are needed so that an application can function within the vendor specific environment. In effect, such a middleware represents a potential lock-in for a customer seeking an IaaS place for an application to run on.
Here is an example of the middleware options – many are mandatory – that must be deployed before an application can be tested and run on Amazon Web Services (AWS), one of the most popular IaaS services:

Depending on the purpose for using IaaS, a customer will have to define the settings for each of the middleware options. This may differ for different situations and can create - de facto - a condition where moving an application to a different IaaS vendor would be laborious.
When it comes to running applications in a production environment, IaaS may not offer an advantage from a cost standpoint. Hosting an application database on the Amazon proprietary offering, such as the Amazon RDS, could ruin the interoperability with related of IaaS databases that are run by other IaaS vendors. This would be so particularly in the case of real-time operations.
SUMMARY
Before DoD proceeds with the placement of its run-time operations with diverse IaaS vendors, DISA must see to it that standards are in place that will assure interoperability and compatibility across proprietary solutions offered by competing IaaS vendors such as Oracle, which supports only Oracle specific IaaS.
Verification of interoperability will have to take place whenever there is an exodus to IaaS providers from the Army, Navy and Air Force instead of consolidating data centers into the Defense Enterprise Computing Centers (DECCs).
Current targets to eliminate most of DoD’s 772 data centers could be potentially met by shifting the computer processing workload to IaaS firms. Contractor headcount will be reduced and computer assets will be removed form DoD books. This will look good because it would deliver reductions that meet OMB numerical targets. However, if such moves are not tightly managed by means of standards, DoD may end up with an even more fractured operating environment than is currently that case.
*http://defensesystems.com/Articles/2011/03/29/Cover-Story-DISA-charts-cloud-strategy.aspx?Page=2
Structure of DoD FY11 Budgets
The IT dashboard, published by the Office of the Federal Chief Information Officer, provides comprehensive information about US Government IT spending for FY11. *
Since the Department of Defense uses 46.2% of total Federal IT spending, the structure of its spending offers useful insights.
Half of systems projects have budgets of less than $1 million. These projects, usually executed as separate local contracts, depend on unique equipment and software configurations. Although these projects account for only 1% of total spending, there is a large population of users that depend on these systems for everyday support. How to migrate such projects into a shared cloud environment is a problem that is waiting for resolution.

The 78 systems with FY11 budgets of more than $100 million are multiyear programs. How to insure interoperability of multiple applications in near real-time, each with diverse databases is a problem that calls for a better resolution. Since these systems are largely under the control of contactors the absence of an overall DoD shared architecture is likely to inhibit a transfer into shared cloud operations.
A more interesting perspective on DoD spending is an examination from the standpoint of the functions IT supports.

The largest share of the budget – 54% - is devoted to “Information Technology Management”, which largely represents investments and operations in DoD IT infrastructure. The “warfighter’s” domain consumes 25% of the IT budget, with logistics using 8% of the total. If one considers that the primary objective of DoD is to support warfighter missions, then a quarter of all IT spending appears to be minimal. However, one must consider that fact that the current IT statistics does not include the costs of military and civilian personnel. It also excludes all IT that has been integrated into weapons. Consequently the relatively small reported share of IT is likely to be misleading.
The remaining 25% is applied to business operations where Supply Chain Management and Human Resources Management are taking the largest shares. This domain is the responsibility of the Chief Management Officer and the Deputy Chief Management Officer.
Systems included in “Information and Technology Management” are critical to the effectiveness of IT. They include the costs of the entire infrastructure, which supports all other functional domains. The top 25 systems, accounting for 62% of this spending are listed as follows:

Most of the above systems can be classified as supporting an infrastructure that has been put in place to support all other systems. The remaining 410 Information Technology Management systems include a number of systems that can be classified as “infrastructure” (which includes security) rather than supporting applications.
SUMMARY
A review of DoD FY11 budgets shows that a disproportionately large share of resources is committed to paying for numerous infrastructures. When this is compared with commercial practice, DoD spending on Information Technology Management can be viewed as disproportionate.
In comparison with prior budget data, the importance of Information Technology Management/Infrastructure has increased from 47% in FY07 to 54%. Meanwhile, the share of the budget dedicated to warfighting missions has declined form 36% in FY07 to 25% in FY11. How much of that can be dues to mis-counting by OMB is not clear. However, a review of itemized systems shows that DoD has been increasingly shifting money into its infrastructure by constructing new systems in this function.

One of the explanations for such proliferation is historical. Most of the large multi-year and multi-billion programs have involved contracts that included the creation of unique infrastructures.
Perhaps the most critical reason for such diversity is the separation of accountability for spending. Warfighter and business application budgets are included in Army, Navy, Air Force and Agencies development costs. After that the diverse Acquisition organizations handed over operations either back to the Army, Navy or Air Force, or to Agencies that starting taking over the management of infrastructures.
* http://it.usaspending.gov/data_feeds
Since the Department of Defense uses 46.2% of total Federal IT spending, the structure of its spending offers useful insights.
Half of systems projects have budgets of less than $1 million. These projects, usually executed as separate local contracts, depend on unique equipment and software configurations. Although these projects account for only 1% of total spending, there is a large population of users that depend on these systems for everyday support. How to migrate such projects into a shared cloud environment is a problem that is waiting for resolution.

The 78 systems with FY11 budgets of more than $100 million are multiyear programs. How to insure interoperability of multiple applications in near real-time, each with diverse databases is a problem that calls for a better resolution. Since these systems are largely under the control of contactors the absence of an overall DoD shared architecture is likely to inhibit a transfer into shared cloud operations.
A more interesting perspective on DoD spending is an examination from the standpoint of the functions IT supports.

The largest share of the budget – 54% - is devoted to “Information Technology Management”, which largely represents investments and operations in DoD IT infrastructure. The “warfighter’s” domain consumes 25% of the IT budget, with logistics using 8% of the total. If one considers that the primary objective of DoD is to support warfighter missions, then a quarter of all IT spending appears to be minimal. However, one must consider that fact that the current IT statistics does not include the costs of military and civilian personnel. It also excludes all IT that has been integrated into weapons. Consequently the relatively small reported share of IT is likely to be misleading.
The remaining 25% is applied to business operations where Supply Chain Management and Human Resources Management are taking the largest shares. This domain is the responsibility of the Chief Management Officer and the Deputy Chief Management Officer.
Systems included in “Information and Technology Management” are critical to the effectiveness of IT. They include the costs of the entire infrastructure, which supports all other functional domains. The top 25 systems, accounting for 62% of this spending are listed as follows:

Most of the above systems can be classified as supporting an infrastructure that has been put in place to support all other systems. The remaining 410 Information Technology Management systems include a number of systems that can be classified as “infrastructure” (which includes security) rather than supporting applications.
SUMMARY
A review of DoD FY11 budgets shows that a disproportionately large share of resources is committed to paying for numerous infrastructures. When this is compared with commercial practice, DoD spending on Information Technology Management can be viewed as disproportionate.
In comparison with prior budget data, the importance of Information Technology Management/Infrastructure has increased from 47% in FY07 to 54%. Meanwhile, the share of the budget dedicated to warfighting missions has declined form 36% in FY07 to 25% in FY11. How much of that can be dues to mis-counting by OMB is not clear. However, a review of itemized systems shows that DoD has been increasingly shifting money into its infrastructure by constructing new systems in this function.

One of the explanations for such proliferation is historical. Most of the large multi-year and multi-billion programs have involved contracts that included the creation of unique infrastructures.
Perhaps the most critical reason for such diversity is the separation of accountability for spending. Warfighter and business application budgets are included in Army, Navy, Air Force and Agencies development costs. After that the diverse Acquisition organizations handed over operations either back to the Army, Navy or Air Force, or to Agencies that starting taking over the management of infrastructures.
* http://it.usaspending.gov/data_feeds
Open Source Middleware for Access to Cloud Services
Transferring applications to a cloud offers enormous cost reductions. It also can be a trap. After placing an application on IaaS it becomes wedged into a unique software environment. For all practical purposes applications cease to be transportable from one IaaS to another IaaS. There are hundreds of cloud services that operate in this manner. IaaS is useful in offering raw computing power but it is not sufficiently flexible how it can be redeployed when conditions change.
Applications can be also placed in a Platform-as-a-Service (PaaS) cloud. All you have to do is to comply with the specific Application Interface (API) instructions and your application will run. Google, Microsoft Azure, a version of Amazon PaaS as well as other cloud services work in this way. After applications are placed in a particular cloud environment they must comply with a long list of required formats. For instance, various PaaS vendors may limit what software “frameworks” can be applied. Such “frameworks” include reusable libraries of subsystem offered by software tools such as Ruby, Java, Node.js and Grails. Some PaaS vendors may also restrict what operating systems (such as which version of Microsoft OS) can be installed. Consequently, PaaS applications will not be always transportable from one cloud vendor to another.
To support the future growth in cloud computing customers must be able to switch from one cloud vendor to another. What follows is restricted to only PaaS cases. This requires that cloud operators must offer the following features:
1. The interface between customer applications and the PaaS must be in the form of Open Source middleware, which complies with approved IEEE standards. Standard Open Source middleware will allows any application to run on any vendors’ PaaS cloud. Regardless how an application was coded it will remain transportable to any cloud, anywhere.
2. The isolation of the customer’s applications from the PaaS software and hardware will permit the retention of the customers’ intellectual property right, regardless of which cloud it may be hosted.
3. Certification by the cloud vendor to customers that that applications will remain portable regardless of configuration changes made to PaaS. This includes assurances that applications will retain the capacity for fail-over hosting by another PaaS vendor.
4. Assurance that the customers’ application code will not be altered in the PaaS cloud, regardless of the software framework used the build it.
This week, VMware introduced a new PaaS software offering called Cloud Foundry. It is available as open source software. It provides a platform for building, deploying and running cloud apps that make it possible for cloud vendors to comply with the four features listed above. Cloud Foundry is an application platform, which includes a self-service application execution engine, an automation engine for application deployment, a scriptable command line interface and development tools that ease the applications deployment processes. Cloud Foundry offers developers the tools to build out applications on public clouds, private clouds and anyplace else, whether the underlying server runs VMware or not.
Cloud Foundry is the first open PaaS that supports services to cloud firms such as Rackspace or Terremark. Cloud Foundry can be also deployed behind firewalls for enterprises can run this software as a private cloud. There is also a version of Cloud Foundry, the “Micro Cloud”, which can be installed on a personal lap top so developers can write code themselves, and then push to whichever cloud they choose. “Micro Cloud” should be therefore understood as a single developer instance of Cloud Foundry.
Cloud Foundry aims to allow developers to remove the cost and complexity of configuring infrastructure and runtime environments for applications so that they can focus on the application logic. Cloud Foundry streamlines the development, delivery and operations of modern applications, enhancing the ability of developers to deploy, run and scale applications into the cloud environment while preserving the widest choice of public and private clouds.
The objective is to get an application deployed without becoming engaged in all kinds of set-ups, such as server provisioning, specifying database parameters, inserting middleware and then testing that it’s all set up after coordinating with the data center operating personnel to accept new run-time documentation. The Cloud Foundry offers an open architecture to handle choices of developer frameworks. It accommodates choices of application infrastructure services. It enables the choosing from a variety of commercially available clouds.
Cloud Foundry overcomes limitations found in today’s PaaS solutions. Present PaaS offerings by commercial firms are held back by limited or non-standard support of development frameworks, by a lack in the variety of application services and especially in the inability to deploy applications across diverse public and private clouds.
SUMMARY
It is increasingly a prerequisite for modern software development technologies to be available as open source. DoD memorandum of October 16, 2009 offers guidance a preferred use of open source software in order to allow developers to inspect, evaluate and modify the software based on their own needs, as well as avoid the risk of lock-in. Cloud Foundry is now an open source project with a community and source code available on www.cloudfoundry.org. This provides the ultimate in extensibility and allows the community to extend and integrate Cloud Foundry with any framework, application service or infrastructure cloud. It includes a liberal licensing model encourages a broad-based community of contributors.
Cloud Foundry takes an Open Source approach to PaaS. Most of such vendor offerings restrict developer choices of frameworks, application infrastructure services and deployment clouds. The open and extensible nature of Cloud Foundry means developers will not be locked into a single framework, single set of application services or a single cloud. VMware will offer Cloud Foundry as a paid, supported product for customers as well as provide the underlying code so developers can build their own private clouds. VMware will also offer Cloud Foundry as a PaaS service in combination with a recently acquired data center in Las Vegas that presently runs data back-up services for over million customers.
Cloud Foundry allows developers to focus on applications, not machines or middleware. Traditional application deployments require developers to configure and patch systems, maintain middleware and worry about network topologies. Cloud Foundry allows you to focus on your application, not infrastructure, and deploy and scale applications in seconds. In the future interoperability of applications across several PaaS firms will matter to more and more companies especially those starting new systems. Flexibility to choose from a range of available PaaS service will become one of the factors behind the choice of trusting any one firm with the hosting and custody of its data processing.
Any DoD plans to migrate systems into a PaaS environment will henceforth have to consider whether Cloud Foundry software, or a similar offering yet to come, will be in place to assure application portability.
Applications can be also placed in a Platform-as-a-Service (PaaS) cloud. All you have to do is to comply with the specific Application Interface (API) instructions and your application will run. Google, Microsoft Azure, a version of Amazon PaaS as well as other cloud services work in this way. After applications are placed in a particular cloud environment they must comply with a long list of required formats. For instance, various PaaS vendors may limit what software “frameworks” can be applied. Such “frameworks” include reusable libraries of subsystem offered by software tools such as Ruby, Java, Node.js and Grails. Some PaaS vendors may also restrict what operating systems (such as which version of Microsoft OS) can be installed. Consequently, PaaS applications will not be always transportable from one cloud vendor to another.
To support the future growth in cloud computing customers must be able to switch from one cloud vendor to another. What follows is restricted to only PaaS cases. This requires that cloud operators must offer the following features:
1. The interface between customer applications and the PaaS must be in the form of Open Source middleware, which complies with approved IEEE standards. Standard Open Source middleware will allows any application to run on any vendors’ PaaS cloud. Regardless how an application was coded it will remain transportable to any cloud, anywhere.
2. The isolation of the customer’s applications from the PaaS software and hardware will permit the retention of the customers’ intellectual property right, regardless of which cloud it may be hosted.
3. Certification by the cloud vendor to customers that that applications will remain portable regardless of configuration changes made to PaaS. This includes assurances that applications will retain the capacity for fail-over hosting by another PaaS vendor.
4. Assurance that the customers’ application code will not be altered in the PaaS cloud, regardless of the software framework used the build it.
This week, VMware introduced a new PaaS software offering called Cloud Foundry. It is available as open source software. It provides a platform for building, deploying and running cloud apps that make it possible for cloud vendors to comply with the four features listed above. Cloud Foundry is an application platform, which includes a self-service application execution engine, an automation engine for application deployment, a scriptable command line interface and development tools that ease the applications deployment processes. Cloud Foundry offers developers the tools to build out applications on public clouds, private clouds and anyplace else, whether the underlying server runs VMware or not.
Cloud Foundry is the first open PaaS that supports services to cloud firms such as Rackspace or Terremark. Cloud Foundry can be also deployed behind firewalls for enterprises can run this software as a private cloud. There is also a version of Cloud Foundry, the “Micro Cloud”, which can be installed on a personal lap top so developers can write code themselves, and then push to whichever cloud they choose. “Micro Cloud” should be therefore understood as a single developer instance of Cloud Foundry.
Cloud Foundry aims to allow developers to remove the cost and complexity of configuring infrastructure and runtime environments for applications so that they can focus on the application logic. Cloud Foundry streamlines the development, delivery and operations of modern applications, enhancing the ability of developers to deploy, run and scale applications into the cloud environment while preserving the widest choice of public and private clouds.
The objective is to get an application deployed without becoming engaged in all kinds of set-ups, such as server provisioning, specifying database parameters, inserting middleware and then testing that it’s all set up after coordinating with the data center operating personnel to accept new run-time documentation. The Cloud Foundry offers an open architecture to handle choices of developer frameworks. It accommodates choices of application infrastructure services. It enables the choosing from a variety of commercially available clouds.
Cloud Foundry overcomes limitations found in today’s PaaS solutions. Present PaaS offerings by commercial firms are held back by limited or non-standard support of development frameworks, by a lack in the variety of application services and especially in the inability to deploy applications across diverse public and private clouds.
SUMMARY
It is increasingly a prerequisite for modern software development technologies to be available as open source. DoD memorandum of October 16, 2009 offers guidance a preferred use of open source software in order to allow developers to inspect, evaluate and modify the software based on their own needs, as well as avoid the risk of lock-in. Cloud Foundry is now an open source project with a community and source code available on www.cloudfoundry.org. This provides the ultimate in extensibility and allows the community to extend and integrate Cloud Foundry with any framework, application service or infrastructure cloud. It includes a liberal licensing model encourages a broad-based community of contributors.
Cloud Foundry takes an Open Source approach to PaaS. Most of such vendor offerings restrict developer choices of frameworks, application infrastructure services and deployment clouds. The open and extensible nature of Cloud Foundry means developers will not be locked into a single framework, single set of application services or a single cloud. VMware will offer Cloud Foundry as a paid, supported product for customers as well as provide the underlying code so developers can build their own private clouds. VMware will also offer Cloud Foundry as a PaaS service in combination with a recently acquired data center in Las Vegas that presently runs data back-up services for over million customers.
Cloud Foundry allows developers to focus on applications, not machines or middleware. Traditional application deployments require developers to configure and patch systems, maintain middleware and worry about network topologies. Cloud Foundry allows you to focus on your application, not infrastructure, and deploy and scale applications in seconds. In the future interoperability of applications across several PaaS firms will matter to more and more companies especially those starting new systems. Flexibility to choose from a range of available PaaS service will become one of the factors behind the choice of trusting any one firm with the hosting and custody of its data processing.
Any DoD plans to migrate systems into a PaaS environment will henceforth have to consider whether Cloud Foundry software, or a similar offering yet to come, will be in place to assure application portability.
How to Fit DoD into the Cloud Environment?
It is now an OMB policy that DoD should start migrating into an architecture that is based on cloud-like concepts. * There are leaders who have suggested that transporting DoD applications into a Google-like environment would solve persistent problems with security, interoperability and cost.
Before anyone can subscribe to a cloud-centered solution it may be useful to examine the current state of DoD applications. What we have now is fractured and often broken, non-standard, custom-fitted and without a shared data environment.
To move thousands of such systems into a well-ordered Platform-as-a-Service or Infrastructure-as-a-Service will require enormous expenditures. It will require restructuring how systems are designed, how they can run and in what data centers they can operate.
To gain a better understanding, in a constrained budgetary environment, it may be useful to examine what are the “as-is” conditions of the existing systems before making “to-be” projections. Most importantly any plans need to be supported by funding commitments and a realistic schedule.
The OSD Deputy Chief Management Officer has defined the scope of work that needs to be done. ** It includes a list of 2,319 systems costing $23.6 billion, which represents 69% of the total DoD IT spending in FY11. *** Of the 2,319 listed systems 1,165 systems are obsolete (e.g. "legacy" or "interim"). 1,154 were labeled as systems that will survive (e.g. "core").
The following statistic shows the number of DoD business systems plotted against their respective FY11 budgets: ****
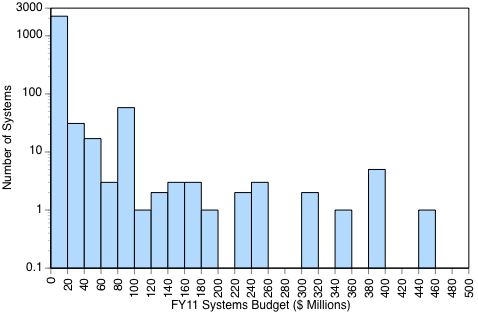
94% of the DoD 2.319 systems have budgets of less than a $20 million, with most operating with budgets of less that $1 million in FY11.
Most of these applications are categorized either as “legacy” systems to be phased out, or as “interim” systems, which have a limited life expectancy. There are 1,165 such systems, or 55% of the DoD total, which are obsolete and require ultimate replacement.
How DoD systems are distributed is illustrated in the following table. Each of these systems will contain numerous applications:

The above table shows that about half of all systems are in Financial Management and in Human Resources areas. The Business Transformation Agency, now discontinued, had spent six years attempting to unify these applications, but a large number remain in place nevertheless. Numerous independent Agencies also control 613 systems systems. Such diversification into different organizations will make any consolidations very difficult.
SUMMARY
The current proposals to ultimately merge 1,165 obsolete systems into 1,154 “core” systems may not be executable. The problem lies not with the proliferation of systems (each supporting many applications) but in the contractual arrangements for small systems, each possessing its unique infrastructure. Most of the current 2,319 systems have been built one contract at a time over a period of decades. Limitations on funding have worked out so that most of these systems ended up will unique configurations of operating systems, diverse application codes, incompatible communications and data bases that are not interoperable. With over 76% of software maintenance and upgrade in the hands of contractors incompatibilities were then a natural outcome. Meanwhile, DoD's high turnover in managerial oversight resulted in a shift of architectural control over system design to contractors.
There is no reason why the Army should not have 252 human resources systems and even more applications. There is no reason why the Navy should not have 92 financial systems with hundreds of diverse applications to manage its affairs. The issue is not the number of reporting formats - that must server diverse user needs - but the costs of funding completely separate systems to deliver such variety.
Over 60% of the current costs for Operations and Maintenance are consumed in supporting hundreds and possibly thousands of separate communications, data management and security infrastructures. Instead of such great multiplicity of infrastructures, we need only a few shared infrastructures that should be the support all of DoD's systems.
If DoD can acquire a Platform-as-a-Service or an Infrastructure-as-a-Service capability, the Army, Navy, Air Force and Agencies will be able to generate and test quickly many inexpensive (and quickly adaptable) applications to be placed on top of a few shared infrastructures. Such an arrangement would results in much cheaper applications.
DoD should not proceed with the re-writing of existing systems as has been proposed. DoD should not proceed with the consolidation of existing systems into a smaller number of surviving systems. Consolidations are slow, expensive and take a very long time,
Instead, DoD should re-direct its efforts to completely separate its infrastructure and data management from applications. The new direction should be: thousands of rapidly adaptable applications, but only a few secure cloud infrastructures for support.
* U.S. Chief Information Officer, Federal Cloud Computing Strategy, February 8, 2011
** http://dcmo.defense.gov/etp/FY2011/home.html (Master List of Systems)
*** DoD IT spending excludes the costs of the military and civilian IT workforce.
**** There are only eight projects reported with budgets greater than $500 million.
Before anyone can subscribe to a cloud-centered solution it may be useful to examine the current state of DoD applications. What we have now is fractured and often broken, non-standard, custom-fitted and without a shared data environment.
To move thousands of such systems into a well-ordered Platform-as-a-Service or Infrastructure-as-a-Service will require enormous expenditures. It will require restructuring how systems are designed, how they can run and in what data centers they can operate.
To gain a better understanding, in a constrained budgetary environment, it may be useful to examine what are the “as-is” conditions of the existing systems before making “to-be” projections. Most importantly any plans need to be supported by funding commitments and a realistic schedule.
The OSD Deputy Chief Management Officer has defined the scope of work that needs to be done. ** It includes a list of 2,319 systems costing $23.6 billion, which represents 69% of the total DoD IT spending in FY11. *** Of the 2,319 listed systems 1,165 systems are obsolete (e.g. "legacy" or "interim"). 1,154 were labeled as systems that will survive (e.g. "core").
The following statistic shows the number of DoD business systems plotted against their respective FY11 budgets: ****
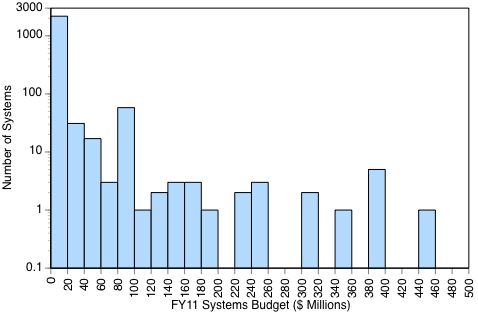
94% of the DoD 2.319 systems have budgets of less than a $20 million, with most operating with budgets of less that $1 million in FY11.
Most of these applications are categorized either as “legacy” systems to be phased out, or as “interim” systems, which have a limited life expectancy. There are 1,165 such systems, or 55% of the DoD total, which are obsolete and require ultimate replacement.
How DoD systems are distributed is illustrated in the following table. Each of these systems will contain numerous applications:
The above table shows that about half of all systems are in Financial Management and in Human Resources areas. The Business Transformation Agency, now discontinued, had spent six years attempting to unify these applications, but a large number remain in place nevertheless. Numerous independent Agencies also control 613 systems systems. Such diversification into different organizations will make any consolidations very difficult.
SUMMARY
The current proposals to ultimately merge 1,165 obsolete systems into 1,154 “core” systems may not be executable. The problem lies not with the proliferation of systems (each supporting many applications) but in the contractual arrangements for small systems, each possessing its unique infrastructure. Most of the current 2,319 systems have been built one contract at a time over a period of decades. Limitations on funding have worked out so that most of these systems ended up will unique configurations of operating systems, diverse application codes, incompatible communications and data bases that are not interoperable. With over 76% of software maintenance and upgrade in the hands of contractors incompatibilities were then a natural outcome. Meanwhile, DoD's high turnover in managerial oversight resulted in a shift of architectural control over system design to contractors.
There is no reason why the Army should not have 252 human resources systems and even more applications. There is no reason why the Navy should not have 92 financial systems with hundreds of diverse applications to manage its affairs. The issue is not the number of reporting formats - that must server diverse user needs - but the costs of funding completely separate systems to deliver such variety.
Over 60% of the current costs for Operations and Maintenance are consumed in supporting hundreds and possibly thousands of separate communications, data management and security infrastructures. Instead of such great multiplicity of infrastructures, we need only a few shared infrastructures that should be the support all of DoD's systems.
If DoD can acquire a Platform-as-a-Service or an Infrastructure-as-a-Service capability, the Army, Navy, Air Force and Agencies will be able to generate and test quickly many inexpensive (and quickly adaptable) applications to be placed on top of a few shared infrastructures. Such an arrangement would results in much cheaper applications.
DoD should not proceed with the re-writing of existing systems as has been proposed. DoD should not proceed with the consolidation of existing systems into a smaller number of surviving systems. Consolidations are slow, expensive and take a very long time,
Instead, DoD should re-direct its efforts to completely separate its infrastructure and data management from applications. The new direction should be: thousands of rapidly adaptable applications, but only a few secure cloud infrastructures for support.
* U.S. Chief Information Officer, Federal Cloud Computing Strategy, February 8, 2011
** http://dcmo.defense.gov/etp/FY2011/home.html (Master List of Systems)
*** DoD IT spending excludes the costs of the military and civilian IT workforce.
**** There are only eight projects reported with budgets greater than $500 million.
Cyber Attack on RSA
RSA (named after the inventors of public key cryptography Ron Rivest, Adi Shamir and Leonard Adleman) is one of the foremost providers of security, risk and compliance solutions. When RSA SecureID token was recently attacked and compromised, this raised the question of how good are the safeguards of the keepers of everybody’s security safeguards. *
The RSA attack was waged in the form of an Advanced Persistent Threat (APT). Information was getting extracted from RSA's protectors of the RSA’s SecurID two-factor authentication products.
“The attacker in this case sent two different phishing emails over a two-day period. The two emails were sent to two small groups of employees who were not high profile or high value targets. The email subject line read '2011 Recruitment Plan. The email was crafted well enough to trick one of the employees to retrieve it from their Junk mail folder, and open the attached excel file. It was a spreadsheet titled '2011 Recruitment plan.xls. The spreadsheet contained a zero-day exploit that installs a backdoor through Adobe Flash vulnerability (CVE-2011-0609).” **
The attack on RSA can be considered to be a textbook example of a targeted phishing attack, or a “spear fishing attack”. What the attacker goes after and obtains once inside the compromised network largely depends on which user he was able to fool and what were the victim's access rights and position in the organization.
The malware that the attacker installed was a variant of the well-known Poison Ivy remote administration tool, which then connected to a remote machine. The emails were circulated to a small group of RSA employees. At least one must have pulled the message out of a spam folder, opened it and then opened the malicious attachment.
In studying the attack form RSA concluded that the attacker first harvested access credentials from the compromised users (user, domain admin, and service accounts). Then proceeded with an escalation on non-administrative users that had access to servers that contained the critically protected “seed” number that is used to generate SecureID numbers ever 60 seconds.
The process used by the attacker was not only sophisticated but also complex, involving several methods: "The attacker in the RSA case established access to staging servers at key aggregation points; this was done to get ready for extraction. Then they went into the servers of interest, removed data and moved it to internal staging servers where the data was aggregated, compressed and encrypted for extraction. The attacker then used FTP to transfer many passwords protected by the RSA file server to an outside staging server at an external, compromised machine at a hosting provider. The files were subsequently pulled by the attacker and removed from the external compromised host to remove any traces of the attack.” *** It can be assumed that the attacker must have had inside information how the RSA methods could be exploited.
SUMMARY
The successful penetration of a highly guarded and well protected source of an RSA security offering should be seen as a warning that a persistent and highly skilled attacker can break down even the strongest defenses.
In this case we have a “spear fishing” exploit, which shows that the attacker must have possessed a great deal of inside information in order to direct the placement of the Poison Ivy tools. Using a known vulnerability (in Adobe Flash) as a vehicle only shows that multiple exploit vehicles can be exploited simultaneously to achieve the desired results.
As is almost always the case, it was a human lapse that allowed the attack on RSA to proceed. Opening a plausibly labeled attachment to e-mail is something that can happen easily, even by people who have special security training.
The only known remedy in a situation like the RSA attack, assuming that somebody, somewhere would be easily fooled to open an attachment, is to enforce the discipline of permitting the opening of e-mails only from persons whose identify is independently certified. Even then there is always a possibility that an invalid certification of identity may somehow creep into DoD. Consequently, a high priority must be placed on instant revocation of any PKI certification of identity.
*http://www.rsa.com/node.aspx?id=3872
** https://threatpost.com/en_us/blogs/rsa-securid-attack-was-phishing-excel-spreadsheet-040111
*** Adobe Flash vulnerability (CVE-2011-0609)
The RSA attack was waged in the form of an Advanced Persistent Threat (APT). Information was getting extracted from RSA's protectors of the RSA’s SecurID two-factor authentication products.
“The attacker in this case sent two different phishing emails over a two-day period. The two emails were sent to two small groups of employees who were not high profile or high value targets. The email subject line read '2011 Recruitment Plan. The email was crafted well enough to trick one of the employees to retrieve it from their Junk mail folder, and open the attached excel file. It was a spreadsheet titled '2011 Recruitment plan.xls. The spreadsheet contained a zero-day exploit that installs a backdoor through Adobe Flash vulnerability (CVE-2011-0609).” **
The attack on RSA can be considered to be a textbook example of a targeted phishing attack, or a “spear fishing attack”. What the attacker goes after and obtains once inside the compromised network largely depends on which user he was able to fool and what were the victim's access rights and position in the organization.
The malware that the attacker installed was a variant of the well-known Poison Ivy remote administration tool, which then connected to a remote machine. The emails were circulated to a small group of RSA employees. At least one must have pulled the message out of a spam folder, opened it and then opened the malicious attachment.
In studying the attack form RSA concluded that the attacker first harvested access credentials from the compromised users (user, domain admin, and service accounts). Then proceeded with an escalation on non-administrative users that had access to servers that contained the critically protected “seed” number that is used to generate SecureID numbers ever 60 seconds.
The process used by the attacker was not only sophisticated but also complex, involving several methods: "The attacker in the RSA case established access to staging servers at key aggregation points; this was done to get ready for extraction. Then they went into the servers of interest, removed data and moved it to internal staging servers where the data was aggregated, compressed and encrypted for extraction. The attacker then used FTP to transfer many passwords protected by the RSA file server to an outside staging server at an external, compromised machine at a hosting provider. The files were subsequently pulled by the attacker and removed from the external compromised host to remove any traces of the attack.” *** It can be assumed that the attacker must have had inside information how the RSA methods could be exploited.
SUMMARY
The successful penetration of a highly guarded and well protected source of an RSA security offering should be seen as a warning that a persistent and highly skilled attacker can break down even the strongest defenses.
In this case we have a “spear fishing” exploit, which shows that the attacker must have possessed a great deal of inside information in order to direct the placement of the Poison Ivy tools. Using a known vulnerability (in Adobe Flash) as a vehicle only shows that multiple exploit vehicles can be exploited simultaneously to achieve the desired results.
As is almost always the case, it was a human lapse that allowed the attack on RSA to proceed. Opening a plausibly labeled attachment to e-mail is something that can happen easily, even by people who have special security training.
The only known remedy in a situation like the RSA attack, assuming that somebody, somewhere would be easily fooled to open an attachment, is to enforce the discipline of permitting the opening of e-mails only from persons whose identify is independently certified. Even then there is always a possibility that an invalid certification of identity may somehow creep into DoD. Consequently, a high priority must be placed on instant revocation of any PKI certification of identity.
*http://www.rsa.com/node.aspx?id=3872
** https://threatpost.com/en_us/blogs/rsa-securid-attack-was-phishing-excel-spreadsheet-040111
*** Adobe Flash vulnerability (CVE-2011-0609)
Continuity of Operations in the Cloud
One of the primary benefits from cloud data operations is the capacity to perform complete backups and to support Continuity of Operations Plans (COOP). COOP recovers operations whenever there is a failure.
In the past data centers were small. Files that needed backup were relatively small, hardly ever exceeding a terabyte. Real-time transactions were rare. High priority processing could be handled by acquiring redundant computing assets that matched the unique configurations of each data center. COOP was managed as a bilateral arrangement. Since hardware and software interoperability across data centers was rare, to restart processing at another side was time consuming. Luckily, data centers were operating at a low level of capacity utilization, which made the insertion of unexpected workloads manageable.
The current DoD environment for COOP cannot use the plans that have been set in place during an era when batch processing was the dominant data center workload. Files are now getting consolidated into cross-functional repositories, often approaching petabytes of data. The urgency of restoring operations is much greater as the processing of information supports a workflow that combines diverse activities.
Desktops and laptops, that used to be self-sustaining, are now completely dependent on the restoration of their screens with sub-second response time. There has been a rapid growth in the number of real-time applications that cannot tolerate delays. What used to be bilateral COOP arrangement is not acceptable any more as DoD is pursuing data server consolidations. The merger of data is based on virtualization of all assets that eliminates much of the spare computer processing capacity.
The current conditions dictate that for rapid fail-over backup data centers must be interoperable. Hardware and software configurations must be able to handle interchangeable files and programs. A failure at any one location must allow for the processing the workloads without interruption at another site. To achieve an assured failover the original and the backup sites must be geographically separate to minimize the effects of natural disasters or of man-caused disruptions. What used to be the favorite COOP plan of loading a station wagon and driving relatively short distances with removable disk packs is not feasible any more. Petabyte data files cannot be moved because they do not exist in isolation. Data center operations are tightly wrapped into a complex of hypervisors, security appliances, emulators, translators and communications devices.
Under fail-over conditions the transfers of data between data centers must be manageable. The affected data centers must be able to exchange large amounts of data over high capacity circuits. Is it possible to start thinking about a COOP arrangement that will operate with fail-overs that are executed instantly over high capacity circuits? How much circuit capacity is required for claiming that two (or more) data centers could be interchangeable?
The following table shows the capacities of different circuits as well as the size of the files that would be have to be transferred for a workable COOP plan:

Transfers of files between small data centers (each with 10 Terabytes of files) would take up to 28 hours using an extremely high capacity circuit (100 MB/Sec). That is not viable.
DoD transaction processing, including sensor data, involves processing of at least one petabyte per date at present, and probably much more in the future. It would take 17 weeks to back up a single petabyte of data from one data center to another even if the highest available circuit capacity of 100 MB/sec is used. That is clearly not viable.
We must therefore conclude that the idea of achieving fail-over backup capabilities by electronic means cannot be included in any COOP plans.
SUMMARY
COOP for the cloud environment must be based on multiple data centers that operate in synchronization with identical software, with matching technologies of computing assets and with comparable data center management practices. This does not call for a strict comparability of every application. What matters will be an identity of the DoD private cloud to act as a Platform-as-a-Service utility, with standard Application Processing Interfaces (APIs).
OMB has mandated that for FY12 all new DoD applications will have to cloud implementation options. Rethinking how to organize the DoD cloud environment for COOP will dictate how that can be accomplished.
In the past data centers were small. Files that needed backup were relatively small, hardly ever exceeding a terabyte. Real-time transactions were rare. High priority processing could be handled by acquiring redundant computing assets that matched the unique configurations of each data center. COOP was managed as a bilateral arrangement. Since hardware and software interoperability across data centers was rare, to restart processing at another side was time consuming. Luckily, data centers were operating at a low level of capacity utilization, which made the insertion of unexpected workloads manageable.
The current DoD environment for COOP cannot use the plans that have been set in place during an era when batch processing was the dominant data center workload. Files are now getting consolidated into cross-functional repositories, often approaching petabytes of data. The urgency of restoring operations is much greater as the processing of information supports a workflow that combines diverse activities.
Desktops and laptops, that used to be self-sustaining, are now completely dependent on the restoration of their screens with sub-second response time. There has been a rapid growth in the number of real-time applications that cannot tolerate delays. What used to be bilateral COOP arrangement is not acceptable any more as DoD is pursuing data server consolidations. The merger of data is based on virtualization of all assets that eliminates much of the spare computer processing capacity.
The current conditions dictate that for rapid fail-over backup data centers must be interoperable. Hardware and software configurations must be able to handle interchangeable files and programs. A failure at any one location must allow for the processing the workloads without interruption at another site. To achieve an assured failover the original and the backup sites must be geographically separate to minimize the effects of natural disasters or of man-caused disruptions. What used to be the favorite COOP plan of loading a station wagon and driving relatively short distances with removable disk packs is not feasible any more. Petabyte data files cannot be moved because they do not exist in isolation. Data center operations are tightly wrapped into a complex of hypervisors, security appliances, emulators, translators and communications devices.
Under fail-over conditions the transfers of data between data centers must be manageable. The affected data centers must be able to exchange large amounts of data over high capacity circuits. Is it possible to start thinking about a COOP arrangement that will operate with fail-overs that are executed instantly over high capacity circuits? How much circuit capacity is required for claiming that two (or more) data centers could be interchangeable?
The following table shows the capacities of different circuits as well as the size of the files that would be have to be transferred for a workable COOP plan:
Transfers of files between small data centers (each with 10 Terabytes of files) would take up to 28 hours using an extremely high capacity circuit (100 MB/Sec). That is not viable.
DoD transaction processing, including sensor data, involves processing of at least one petabyte per date at present, and probably much more in the future. It would take 17 weeks to back up a single petabyte of data from one data center to another even if the highest available circuit capacity of 100 MB/sec is used. That is clearly not viable.
We must therefore conclude that the idea of achieving fail-over backup capabilities by electronic means cannot be included in any COOP plans.
SUMMARY
COOP for the cloud environment must be based on multiple data centers that operate in synchronization with identical software, with matching technologies of computing assets and with comparable data center management practices. This does not call for a strict comparability of every application. What matters will be an identity of the DoD private cloud to act as a Platform-as-a-Service utility, with standard Application Processing Interfaces (APIs).
OMB has mandated that for FY12 all new DoD applications will have to cloud implementation options. Rethinking how to organize the DoD cloud environment for COOP will dictate how that can be accomplished.
Subscribe to:
Posts (Atom)